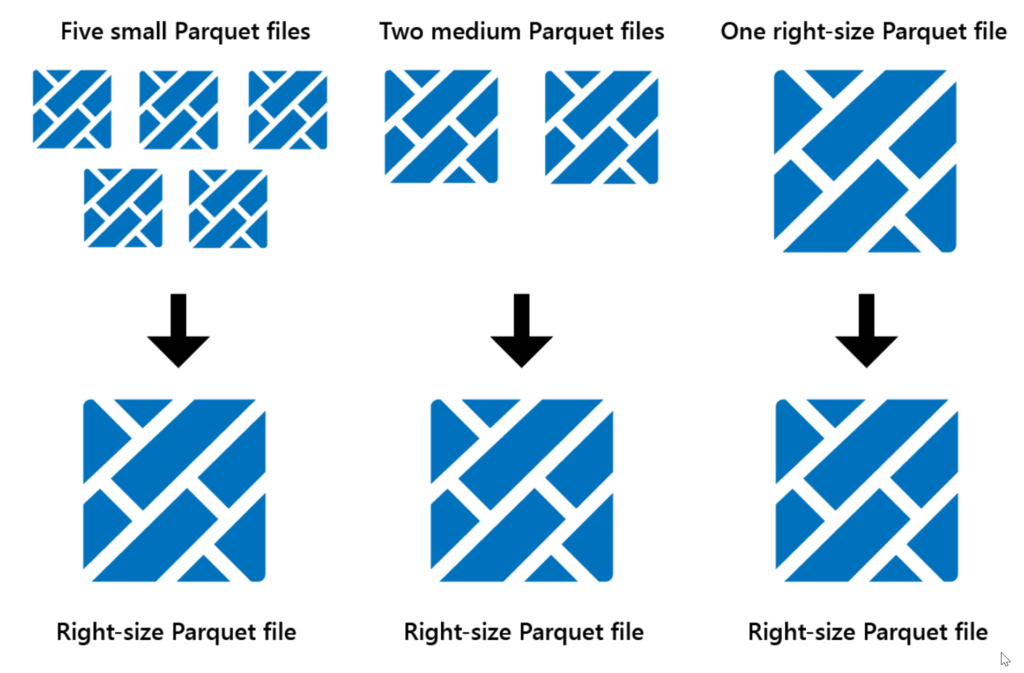
Very simply, we are able to optimize lakehouse data table architecture. In the case where Spark is used, Parquet files are immutable and as such, we end up storing a lot of small files. The Optimize function allows us to reduce the number of files written as it just collates them into larger files.
Within your OneLake environment, we can select the ellipses for a specific database table and select Maintenance to leverage the V-order function.
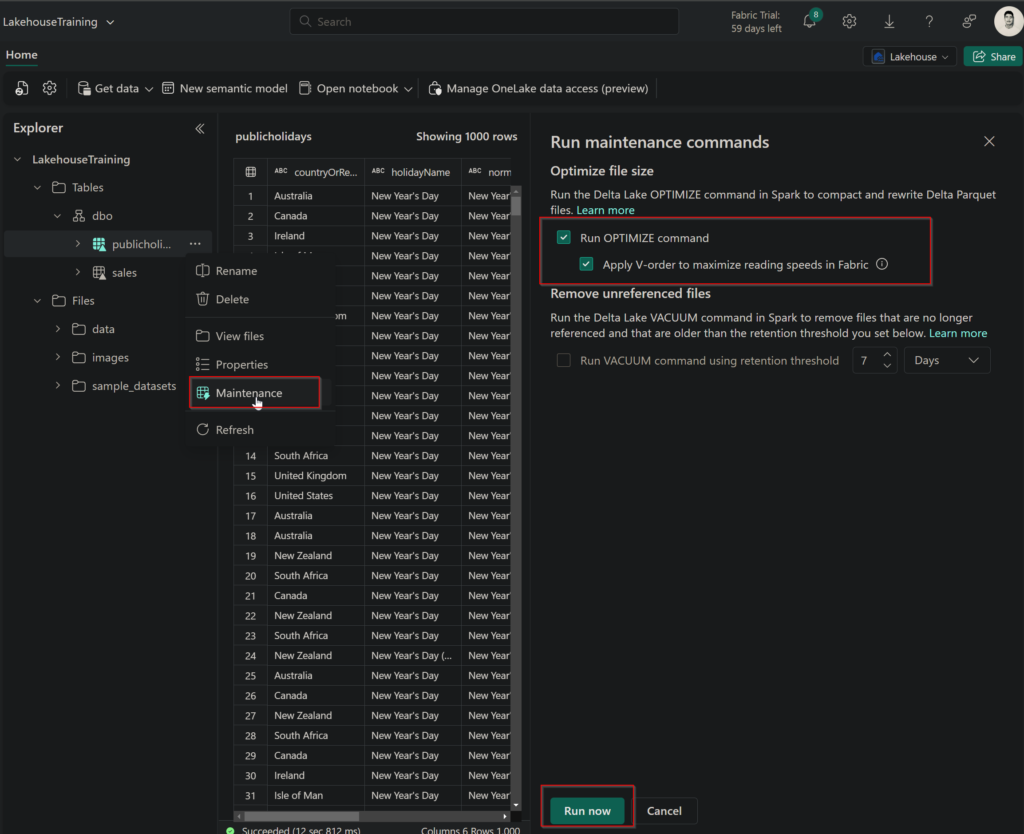
V-Order works by applying special sorting, row group distribution, dictionary encoding, and compression on Parquet files.