The general logic of executing the Onenote data ingest:
- Get OAuth access token from Azure
- Get API call to get all sections of a notebook
- Iterate over all the sections and pages in the notebook and append the section name, section id, page title, page id and html content to the local data list
- In a spark data frame, input the data in a new delta table
- Note, that there may be some Graph API return limits, but you can increase the page size up to a maximum of 999 items per request using the $top query parameter
Onenote data ingest PySpark code:
import requests
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType
# Initialize Spark session
spark = SparkSession.builder.appName(“OneNoteDataPipeline”).getOrCreate()
# Authentication
def get_access_token():
url = “https://login.microsoftonline.com/982d56ce-f6e7-4334-a1c4-5d6779c789a6/oauth2/v2.0/token”
payload = {
“grant_type”: “client_credentials”,
“client_id”: “[client_id]”,
“client_secret”: “[client_secret]”,
“scope”: “https://graph.microsoft.com/.default”,
}
headers = {“Content-Type”: “application/x-www-form-urlencoded”}
response = requests.post(url, data=payload, headers=headers)
if response.status_code == 200:
return response.json()[“access_token”]
else:
raise Exception(f”Failed to get token: {response.status_code}, {response.text}”)
access_token = get_access_token()
headers = {“Authorization”: f”Bearer {access_token}”}
# 1. Get sections
sections_url = “https://graph.microsoft.com/v1.0/users/[user]/notebooks/[notebook]/sections”
sections_response = requests.get(sections_url, headers=headers)
if sections_response.status_code != 200:
raise Exception(f”Failed to get sections: {sections_response.status_code}, {sections_response.text}”)
sections = sections_response.json()[“value”]
# 2. Iterate over sections to get pages
data = []
for section in sections:
section_id = section[“id”]
section_name = section[“displayName”]
pages_url = f”https://graph.microsoft.com/v1.0/users/[user]/onenote/sections/{section_id}/pages”
pages_response = requests.get(pages_url, headers=headers)
if pages_response.status_code != 200:
raise Exception(f”Failed to get pages for section {section_id}: {pages_response.status_code}, {pages_response.text}”)
pages = pages_response.json()[“value”]
# 3. Iterate over pages to get HTML content
for page in pages:
page_id = page[“id”]
page_title = page[“title”]
content_url = f”https://graph.microsoft.com/v1.0/users/[user]/onenote/pages/{page_id}/content”
content_response = requests.get(content_url, headers=headers)
if content_response.status_code != 200:
raise Exception(f”Failed to get content for page {page_id}: {content_response.status_code}, {content_response.text}”)
html_content = content_response.text
# Append the data to the list
data.append((section_name, section_id, page_title, page_id, html_content))
# 4. Store the data in a Delta table in Fabric’s Lakehouse
# Define schema for Spark DataFrame
schema = StructType([
StructField(“section_name”, StringType(), True),
StructField(“section_id”, StringType(), True),
StructField(“page_title”, StringType(), True),
StructField(“page_id”, StringType(), True),
StructField(“html_content”, StringType(), True),
])
# Create Spark DataFrame
df = spark.createDataFrame(data, schema)
# Write to Fabric’s Lakehouse (assuming a Lakehouse connection is set up)
lakehouse_path = “abfss://[email protected]/OneNoteContent.Lakehouse/Tables”
df.write.format(“delta”).mode(“overwrite”).save(lakehouse_path)
print(f”Data saved successfully to {lakehouse_path}”)
This code would be inputted into the lakehouse as a parquet file which then could be transformed into a delta table:

The general logic for the confluence page creation is:
- Create all the custom folders in the appropriate space
- For each folder, based on the record’s section name column, create a new page with the html content in it
import requests
import json
# Load lakehouse data
lakehouse_df = spark.read.format("delta").load(
"abfss://[email protected]/OneNoteContent.Lakehouse/Tables/onenote_content"
)
# Confluence API details
confluence_url = "https://gscs.atlassian.net/wiki/rest/api/content"
username = "[user_name]"
api_token = "[api_token]"
auth = (username, api_token)
# Parent folder ID where folders will be created
parent_folder_id = "25231644" # Replace with your actual parent folder ID
# List of folders to create
folders = [
[list of folders]
]
# Create folders in Confluence
def create_folder(folder_name):
payload = {
"type": "folder",
"title": folder_name,
"space": {"key": "IT"},
"status": "current",
"ancestors": [{"id": parent_folder_id}]
}
response = requests.post(confluence_url, auth=auth, headers={"Content-Type": "application/json"}, json=payload)
if response.status_code == 200:
print(f"Folder '{folder_name}' created successfully.")
return response.json()["id"]
else:
print(f"Failed to create folder '{folder_name}': {response.text}")
return None
# Create folders and store their IDs
folder_ids = {}
for folder in folders:
folder_id = create_folder(folder)
if folder_id:
folder_ids[folder] = folder_id
print("Folder creation completed. Folder IDs:")
print(folder_ids)
# Create pages in Confluence
def create_page(page_title, html_content, ancestor_id):
payload = {
"type": "page",
"title": page_title,
"space": {"key": "IT"},
"status": "current",
"body": {"storage": {"value": html_content, "representation": "storage"}},
"ancestors": [{"id": ancestor_id}]
}
response = requests.post(confluence_url, auth=auth, headers={"Content-Type": "application/json"}, json=payload)
if response.status_code == 200:
print(f"Page '{page_title}' created successfully.")
else:
print(f"Failed to create page '{page_title}': {response.text}")
# Process records in the Delta table and create pages in corresponding folders
for row in lakehouse_df.collect():
section_name = row["section_name"].strip()
page_title = row["page_title"].strip()
html_content = row["html_content"].strip()
# Retrieve the ancestor folder ID for the section, defaulting to a specific folder if not found
ancestor_id = folder_ids.get(section_name, "[default_section_id]") # Default folder ID
create_page(page_title, html_content, ancestor_id)
Conclusion:
By leveraging the pyspark script, I was able to bulk input all the onenote notes into a delta table in lakehouse based on page id, section id and html content. This delta table can then be referenced in a new pyspark script that creates new pages utilizing the html content. This was able to auto-input >300 onenote notes into Confluence; however, the attachments were not able to be properly inputted. This problem will need to be researched a bit more.
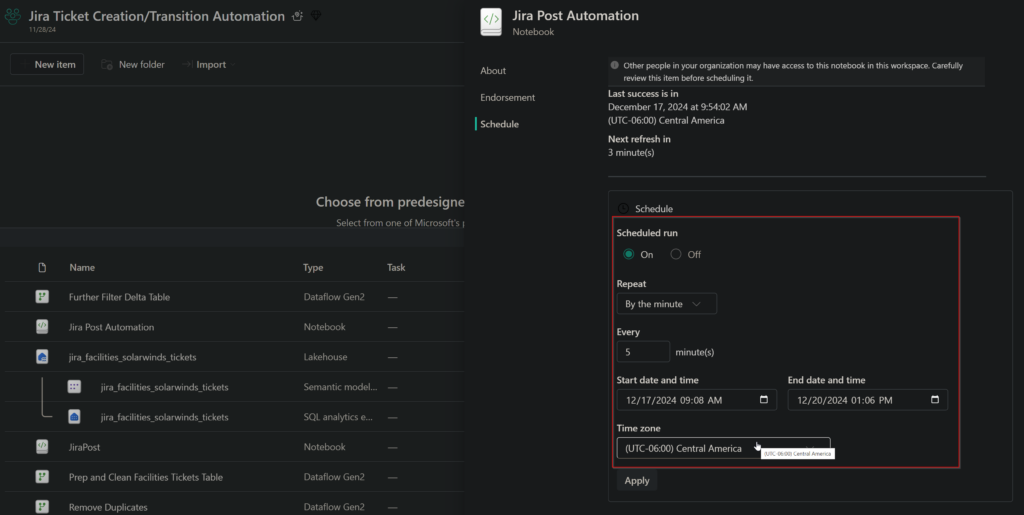
To Automate this in the background:
We can leverage Fabric’s scheduling tool that runs our automation script based on parameters: repeat interval, start time, end time, and time zone.