
We have automated around 100k tickets over to Jira and to clean the Jira production data, some fields need to be altered. By default, some tickets were assigned to Jin as a default user, but this is problematic for reporting and filtering purposes in the future.
As such, we needed to change around 60k tickets that were assigned to Jin to Unassigned. To do this, I accessed the filter feature in Jira to create a JQL query that outputs all the relevant records. We
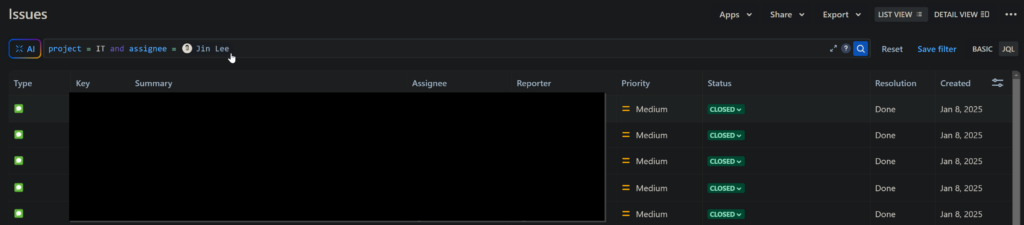
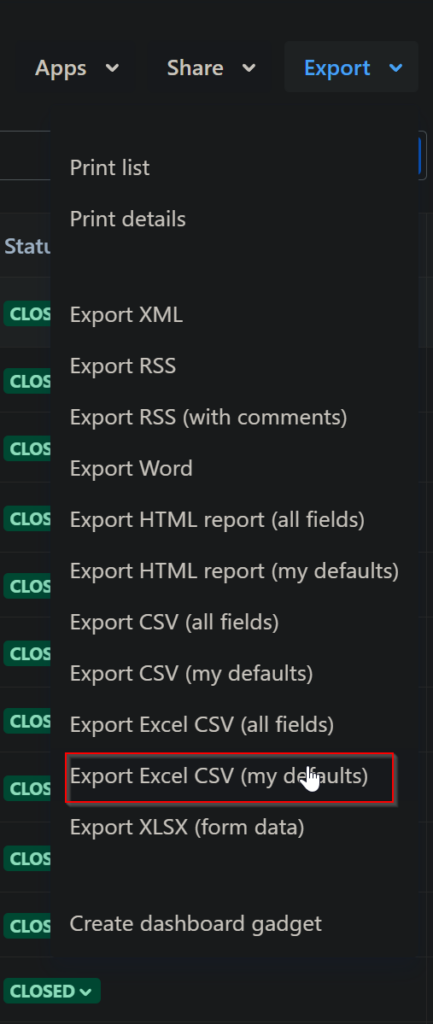
In the top right hand side of the screen, we can export the list in a CSV file.
In Fabric, I created a lakehouse to store the CSV and transitioned it into a Delta table:

Then, in a Spark Notebook, I ran this script in a 5 min scheduled interval for 2 days:
import json
import requests
from datetime import datetime
import re
from pyspark.sql.utils import AnalysisException
from pyspark.sql.types import StructType, StructField, StringType, TimestampType
# Define Lakehouse paths
source_lakehouse_path = "[abs_path]"
# Load the source Delta table
it_tickets_df = spark.read.format('delta').load(source_lakehouse_path)
# Filter the first 100
records = it_tickets_df.limit(100).collect()
# Jira API Configuration
jira_base_url = "[url]"
auth = ("[user]", "[api_token]")
headers = {"Content-Type": "application/json"}
# Initialize list to track successful records
successful_records = []
# Process each record
for record in records:
record_dict = record.asDict()
# Extract fields
key = str(record_dict.get("Key", ""))
print("Ticket Key: " + key)
# Set assignee to unassigned
edit_payload = {
"fields": {
"assignee": {
"name": -1
}
}
}
# API request
edit_issue_response = requests.put(
f"{jira_base_url}/rest/api/3/issue/{key}",
auth=auth, headers=headers, data=json.dumps(edit_payload)
)
if edit_issue_response.status_code == 404 or edit_issue_response.status_code == 400:
print(f"Bad request while adding extra fields to ticket {key}. Skipping extra fields.")
elif edit_issue_response.status_code == 204 or edit_issue_response.status_code == 200:
print(f"Ticket {key} inserted extra fields.")
# Track successful record
successful_records.append(record_dict)
else:
print(f"Unknown ticket status for: {issue_key}")
ids_to_remove = [record["Key"] for record in successful_records]
it_tickets_df.filter(~it_tickets_df["Key"].isin(ids_to_remove)) \
.write.format('delta').mode('overwrite').save(source_lakehouse_path)
print(f"Successfully removed {len(ids_to_remove)} records from the source table.")
Update:
This solution does not work as there are only 1k records that can be exported, but instead we can just open this filtered list in the connected excel app:
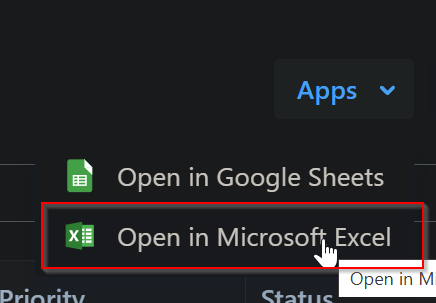
Replacing the csv with this updated one and creating a delta table based on this csv solved the issue.