
Linear Algebra – Refresh
Vector: Magnitude + Direction (5Kmh east = velocity (5,0))
Using Graph API & Pyspark to Move Sharepoint Files

We needed a background script running within our sharepoint directory that would read through a list of files and organize them according to their ids: creating a parent folder with the name of the id or loading the file into an existing id folder. Script:
Creating a Business Central Cloud & Bitbucket CICD Pipeline
In my bitbucket repository, I enabled pipelines and added branch restrictions for security purposes. Also I used Repository variables within in my bitbucket repository associated to my service principal set up in Azure app registration. This CICD pipeline allows my team to merge code to our main branch to auto-deploy-install our extension in our BC […]
Adding an internal PO system into Business Central as a bolt on
I noticed that Business Central’s Purchase Order module is not simple and therefore could be a deterrent for certain users. Since our finance staff have committed to using Business Central, having procurement use the BC inherent PO module would make life easier in terms of data centralization and end-to-end PO to PI auditing. I noticed […]
Transitioning NAV on-prem to BC Cloud in 2025

This process has changed from 10 months ago. NAV on-prem needs to transition to BC14 on-prem to BC 25 on-prem to BC cloud. Pre-requisites: NAV on-prem to BC 14 transition: First follow to upgrade application code: https://learn.microsoft.com/en-us/dynamics365/business-central/dev-itpro/upgrade/upgrading-the-application-code to create application .txt files. Follow the steps here: https://learn.microsoft.com/en-us/dynamics365/business-central/dev-itpro/upgrade/upgrade-unmodified-application-v14-v25 Run the cloud migration setup in a new […]
SQL Server – Freeing up space

Even when I deleted a large database, my drive would not free up space. This required me to go into the DATA folder in the MSSQLSERVER to manually delete the specific database data and log files. This freed up the drive’s storage.
The OSI Model
OSI – Open Systems Interconnection model is a universal language for computer networking. It is based on the concept of splitting up a communication system into seven abstract layers, each one stacked upon the last. 7. Application Layer: Only layer that directly interacts with data from the user. Software applications like web browsers and email […]
Introduction to Networks
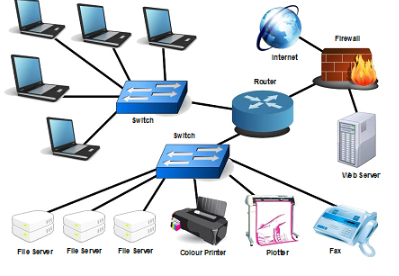
Network: a group or system of interconnected people or things. LAN: local area network – restricted network spanning a particular geographic location such as an office building. Workgroup: set of devices with no security association with one another. (In the context of LANs, this means they are physically in the same network segment) – All […]
How to export existing report layouts and code to customize them to your needs in Business Central

There was a need by my client to modify the existing base Cheque report used in business central’s cheque run process. I did not want to create a new layout from scratch due to time constraints and wanted to leverage existing layouts. First, I checked to see what the report object id was in Report […]
How to update custom column values in Business Central post data migration

I have a scenario where I have migrated base NAV data over to Business Central cloud. Some custom fields for tables were not ported over to the cloud tables. As such, I needed to find a way to create these new fields in the existing tables and back sync data over to these new fields. […]