The most common way to work with data in delta tables in Spark is to use Spark SQL.
Lets say we have a table in OneLake called products:
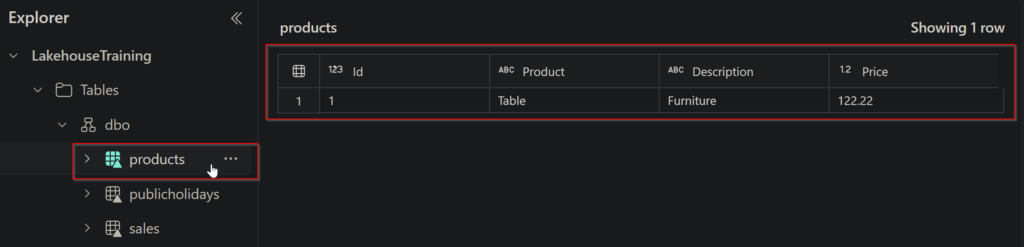
In the connected Spark SQL, we can insert data like so:
spark.sql("INSERT INTO products VALUES (1, 'Widget', 'Accessories', 2.99)")
When you want to work with delta files rather than catalog tables, it may be simpler to use the Delta Lake API. You can create an instance of a DeltaTable from a folder location containing files in delta format, and then use the API to modify the data in the table. You will have to convert the csv file into a delta table first by running this code:
from pyspark.sql import SparkSession
# Initialize Spark session
spark = SparkSession.builder \
.appName("CSV to Delta Conversion") \
.getOrCreate()
# Path to the CSV file and the desired Delta table location
csv_path = "Files/data/products.csv"
delta_path = "Files/data/products"
# Read the CSV file into a DataFrame
df = spark.read.format("csv").option("header", "true").option("inferSchema", "true").load(csv_path)
# Write the DataFrame as a Delta table
df.write.format("delta").mode("overwrite").save(delta_path)
Once that is done, we will see the products delta table.
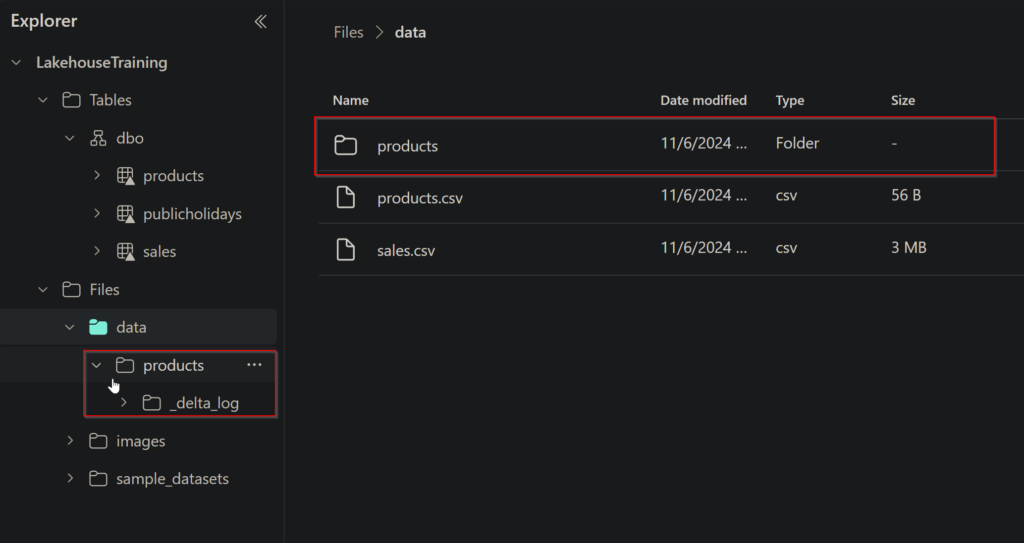
Next, run the code below to create a new parquet file that will have the table update as requested.
from delta.tables import *
from pyspark.sql.functions import *
# Create a DeltaTable object
delta_path = "Files/data/products"
deltaTable = DeltaTable.forPath(spark, delta_path)
# Update the table (reduce price of accessories by 10%)
deltaTable.update(
condition = "Description == 'Accessories'",
set = { "Price": "Price * 0.9" })